The Web Archive of Notícias da Covilhã. Explore the past of this centenary newspaperThe Web Archive of Notícias da Covilhã. Explore the past of this centenary newspaper
About the Project
The ArquivoNC - web archive of the newspaper Notícias da Covilhã - is the result of an academic project developed within the scope of the final course project of the Bachelor's degree in Computer Engineering at the University of Beira Interior (UBI). The project provides access to ten years of web pages from the newspaper Notícias da Covilhã from news preserved by Arquivo.pt between 2009 and 2019.
OBJECTIVES
The growing increase of information published on the web, in the form of texts, images, videos, and audios, has been a distinctive feature of the digital age.
Interestingly, never before have so many contents been lost, preventing current and future generations from accessing a historical record of the web, as we know it today.
In Portugal, the preservation of web content is the responsibility of Arquivo.pt.
The aim of this project is to use the resources of Arquivo.pt to preserve the digital memory of Covilhã and the legacy of the newspaper Notícias da Covilhã by making its historical content easily accessible to researchers and the general public.
The availability of this content through a website dedicated to the web archive of the newspaper aims to contribute to the preservation of local heritage and complement the information available on the current version of the website, recovering access to a set of news, images, and newspaper covers lost in 2019 with the disappearance of the previous version of the website and the end of the weekly printed edition of the newspaper (resumed on March 9, 2023).
ARCHITECTURE
The architecture of this project consists of three distinct modules:
(1) Information Extraction
(2) Indexing, Search, and Similarity
(3) Development and Hosting of the Website
Information Extraction
To implement this project, we used Arquivo.pt. Specifically, we considered the 2979 versions of the website of the newspaper Notícias da Covilhã preserved by Arquivo.pt between 2009 and 2019. To obtain the URLs of the 2979 versions, we used the Python software package "PublicNewsArchive" (Arquivo.pt Award 2022). To automate the extraction of information, we applied web scraping techniques that resulted in the retrieval of 2661 news articles, 1327 images, and 372 newspaper covers. To complement the extracted information and enrich the content of the collected news, we used the YAKE software to extract relevant keywords, and spaCy to identify and extract entities from the text. Finally, using the Text-to-Speech package from Google, we converted the textual information into audio, allowing users to listen to the news article.
Indexing, Search, and Similarity
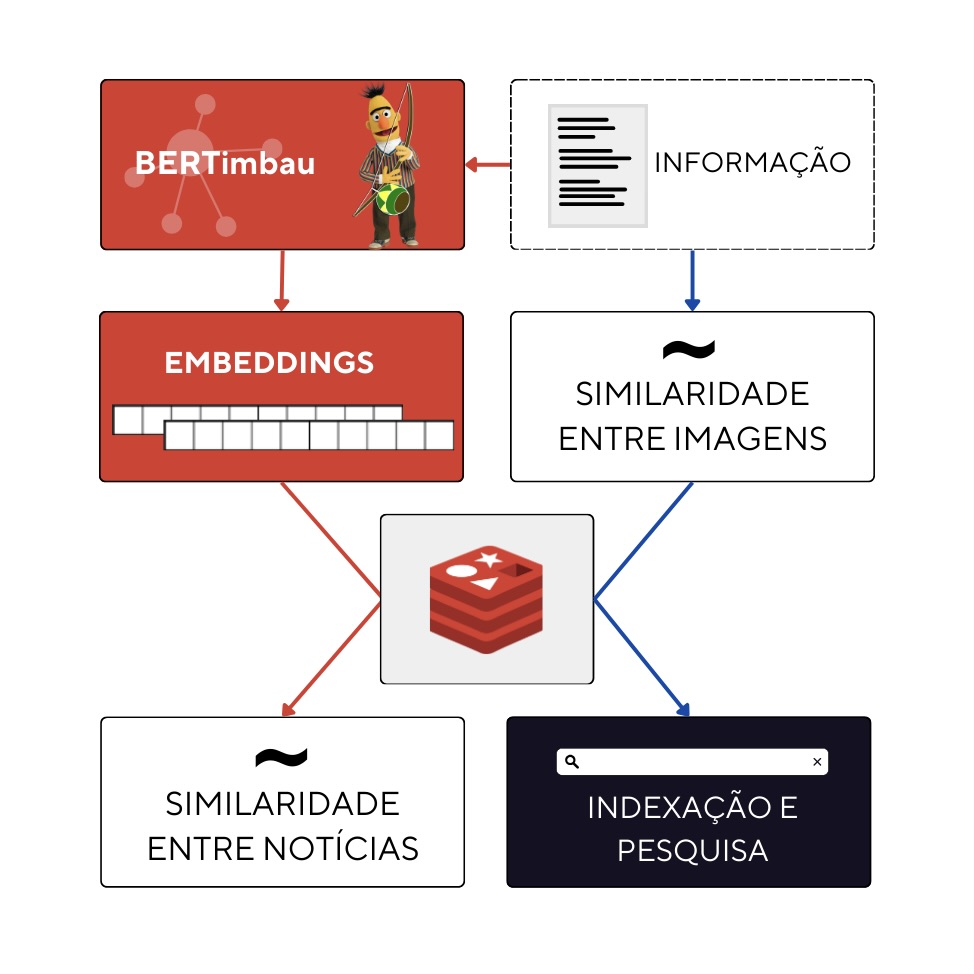
For indexing and searching the extracted data, we used the NoSQL database redis. Specifically, three data indexes were built to respond to different types of searches: news articles, images, and newspaper covers. For example, each element of the news article (such as title, content, date, etc.) is indexed in an inverted index and represented by the frequency of its terms using the TF.IDF (Term Frequency - Inverse Document Frequency) measure.
This traditional approach allows users to search for news containing a specific term (or set of terms) within a given time frame. Additionally, each news article is also represented in the vector space using a 512-dimensional word vector, generated by the natural language model BERTimbau. The semantic representation of each news article enables the application of a similarity search algorithm (Approximate Nearest Neighbors) and forms the basis for one of the main features of this project: the recommendation of past news.
The other two indexes allow users to search within a universe of 1327 images (including similar image recommendations), as well as search for textual elements within the 372 indexed newspaper covers.
Development and Hosting of the Website
For the development of the website, we used the Flask framework and connected it to the NoSQL Redis database to obtain dynamic elements. The virtualization of this architecture is ensured through a Docker system.
The figure below illustrates the architecture supporting the developed system:
(1) Information Extraction
(2) Indexing, Search and Similarity
(3) Website Development and Hosting
CONTRIBUTIONS
With the development of this project, it was possible to recreate the website of Jornal Notícias da Covilhã (2009 - 2019) and recover 10 years of news, images and covers preserved by Arquivo.pt. Among the results obtained with the implementation of the project, the following stand out:
won an honorable mention from the .PT Association at the Arquivo.pt 2024 Award;
the development of a dynamic system that displays past news and covers published on the current day and week, respectively;
the implementation of a search system for news, images and covers of the newspaper;
the introduction of a news recommendation system and image similarity;
the adoption of a system for sharing content (particularly news and covers) on social networks;
the implementation of a text-to-speech system (text2speech), which makes it possible to listen to the news;
AUTHORS
This project was developed by Rodrigo Silva (a student at the University of Beira Interior) under the guidance of Ricardo Campos (Professor at the University of Beira Interior and affiliated with INESCTEC and Ci2@IPT) as part of the project course of the Bachelor's degree in Computer Science and Engineering at the University of Beira Interior (UBI).
Rodrigo Silva
Ricardo Campos
ACKNOWLEDGEMENTS
This project was funded by national funds through the Portuguese funding agency, FCT - Foundation for Science and Technology, within the context of the StorySense project (DOI 10.54499/2022.144 09312.PTDC).
It involved the collaboration of Sérgio Nunes (Systems and Development Area, UBI) and Paulo Crispim (Center for Computer Science and Systems (CIS), IPTomar).